
34. Återkopplande neurala nätverk
Återkopplande neurala nätverk* – recurrent neural networks (RNN) på engelska – är en typ av neurala nätverk som tillåter oss att ta den temporala aspekten av språk i beaktning. Medan framåtriktade neurala nätverk måste ha all information tillgänglig från början och analyserar indatat inom ett givet spann, gör RNN det möjligt att hantera indatat inkrementellt, utan att veta längden på datat på förhand, som vid t.ex. taligenkänning.
Minimikravet för att ett nätverk ska räknas som ett RNN är att värdet hos någon enhet i nätverket är direkt eller indirekt beroende av tidigare utdata som indata (Jurafsky & Martin 2019). En av de enklaste typen av RNN är Elman-nätverk som i grund och botten liknar ett vanligt framåtriktat nätverk med sitt indatalager, gömda lager och utdatalager. Den västentliga skillnaden ligger i den återkoppling som sker i det gömda lagret. Tack vare återkopplingen som sker så beror aktiveringsvärdet i det gömda lagret dels på det nuvarande indatat, och dels på aktiveringsvärdet i det gömda lagret från föregående tidssteg: “[t]he hidden layer from the previous time step provides a form of memory, or context, that encodes earlier processing and informs the decisions to be made at later points in time (Jurafsky & Martin 2019: kap 9: sida 3).
Detta innebär att RNN:et inte ställer några krav på hur stor föregående kontext får vara eftersom kontexten som skickas med från föregående gömda lagers tidssteg även innehåller information från indatasekvensens början. Detta innebär också att aktiveringsvärdet från det gömda lagret i föregående tidssteg måste viktas för att avgöra hur mycket det ska påverka nuvarande indatas utdata. Detta ger upphov till ytterligare en uppsättning viktparamterar i nätverket som precis som andra viktparametrar måste justeras under uppträning via backpropagation, och mer specifikt backpropagation över tid. Den utmärkta föreläsningsvideon nedan från MIT:s introduktionskurs till djupinlärning ligger till grund för resten av den här texten. Kolla på den om du har tid.
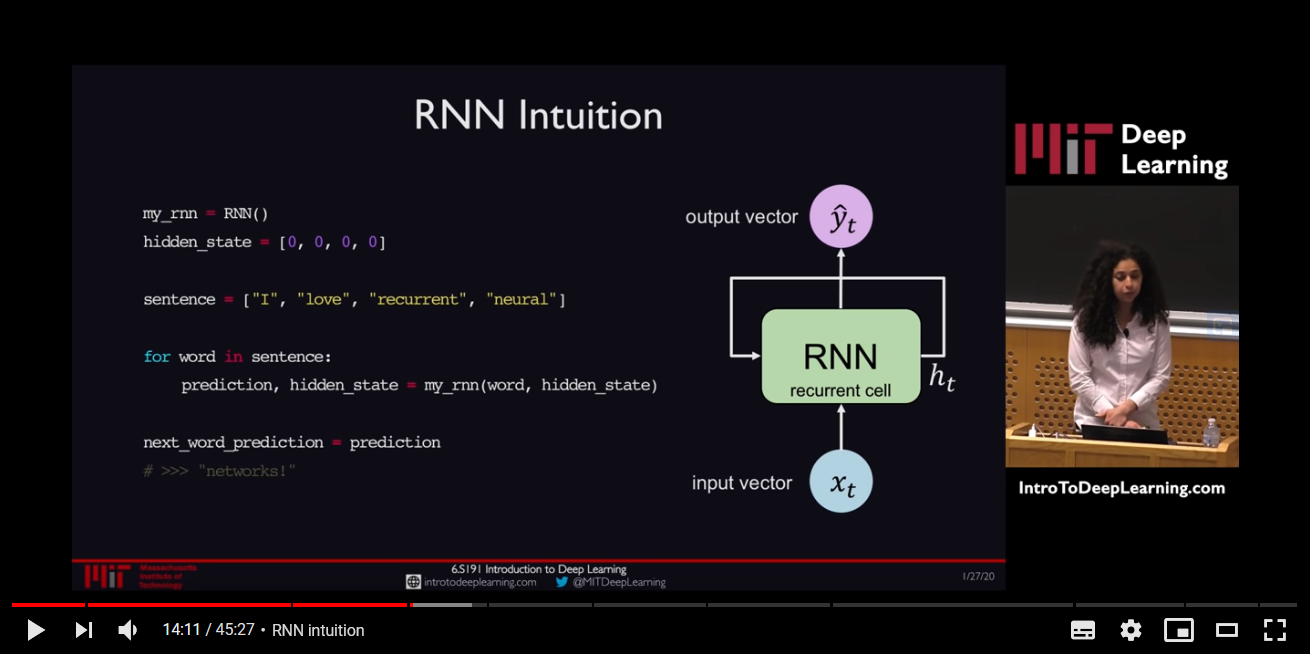
Istället för att skicka tillbaka felgradienten vid ett enda tidssteg som i framåtriktade neurala nätverk görs detta vid varje tidssteg och sedan över samtliga tiddsteg ända tillbaka till början av datasekvensen. Eftersom vi kan ha att göra med många tidssteg, och varje tidssteg måste genomföra en matrismultiplikation med viktmatrisen W samt köra resultatet genom en icke-linjär aktiveringsfunktion, kan vi stöta på två problem. Det ena, exploderande gradient-problemet, beror på att viktmatrisen eller gradieten av aktiveringsfunktioen har många värden över 1, vilket resulterar i stora felgradienter. Detta kan lösas genom något som kallas gradientklippning (eng. gradient clipping) och innebär att skala ner stora gradienter.
Det andra problemet som kan uppstå, försvinnande gradient (eng. vanishing gradient), uppstår till följd av multiplicering av många små värden, vilket leder till att felen i tiddssteg längre tillbaka i nätverket får väldigt små gradienter. Detta kan leda till att nätverket lär sig premiera korta dependenser – dvs. ord som ligger närmare slutet av sekvensen. Det finns flera sätt att åtgärda den försvinnande gradienten, bland annat genom valet av aktiveringsfunktion och hur man initialiserar vikterna. Men en lösning som är kopplad till valet av nätverksarkitektur är LSTM-nätverk (eng. Long Short Term Memory).
LSTM innehåller portar (eng. gates) som kontrollerar informationsflödet i den återkopplandet delen av nätverket. Detta sker genom ett nätverkslager, t.ex. sigmoid, som bestämmer hur mycket av informationen från tidigare tidssteg som ska få flöda igenom (0 = inget, 1 = allt, eller nånting däremellan) samt via pointwise multiplication. Portarna arbetar i fyra steg: 1) först glömmer de bort det som bedöms vara irrelevant från det tidigare tidssteget, 2) därefter utförs beräkningar för att lagra det som är relevant från det nya indatat, 3) sedan kombineras dessa två steg för att uppdatera det inre tillståndet i återkopplingsmodulen, 4) och slutligen generera en output. Det inre celltillstånget, c, gör det möjligt för gradienter att flöda ostört genom tidigare tidssteg och därigenom lösa problemet med försvinnande gradienter. På frågan om hur nätverket avgör vilken information som ska lagras svarar föreläsaren att nätverket måste tränas upp till att förstå vilka ord som bär på rikare semantisk betydelse och därför är värda att spara, som t.ex. “Frankrike” i sekvensen “Jag växte upp i Frankrike, men nu för tiden bor jag i Boston. Jag talar flytande _____“.
* Eftersom hela MLT-programmet är på engelska är det ibland svårt att veta vad den bästa svenska översättningen av begrepp som "recurrent neural networks" egentligen är. Ofta googlar jag, och i det här fallet hittade jag 19 träffar för "återkoppla(n)de neurala nätverk" och 15 för "rekurrenta neurala nätverk". Ordet "rekurrent" ligger närmare engelskan men blir ganska svårbegripligt på svenska. Därför föredrar jag "återkopplande".