
9. Fonetik, fonologi och taligenkänning
Grundidén bakom taligenkänning (eng. speech recognition) och talsyntes (eng. speech synthesis) är samma som den bakom fonologi, nämligen att kunna bryta ner ord och yttranden i mindre beståndsdelar. Skillnaden mellan fonologi å ena sidan, och fonetik å andra, är att fonetik behandlar studiet av lingvistiska ljud (produktionen i den mänskliga talapparaten, den akustiska realiseringen och digitaliseringen av densamma), medan fonologin beskriver hur ljud realiseras i olika lingvistiska system (specifika språk och dialeter), samt hur dessa ljud förhåller sig till resten av grammatiken. Så medan fonetiken behandlar ljud i största allmänhet, i form av foner (de minsta urskiljbara ljudsegmeneten i mänskligt tal), sysslar fonologin istället med fonem (de minsta betydelseskiljande ljuden/fonerna) i ett visst system.
Fonem i form av vokaler och konstanter kombineras i stavelser (eng. syllables) som består av en stavelsekärna (eng. nucleus) i form av en vokal. De kringliggande konsanterna kan delas upp i den initiala ansatsen (eng. onset), t.ex. /s/ i [sol] eller /gr/ i [gris], och en efterföljande koda (eng. coda), t.ex. /l/ i [sol]. Stavelsekärnan plus kodan bildar stavelsens rim (eng. rime). Att bryta ner ord och meningar från mänskligt tal eller skrift till stavelser kallas stavelsedelning (eng. syllabification). Reglerna för vilka fonem som får förekomma tillsammans i en stavelses ansats eller rim i ett givet språk behandlas i det som kallas fonotax (eng. phonotactics). Inom språkteknologin är detta något som antingen kan tas i beaktning genom ett 1) regelstyrt system i form av en villkorslista eller en ändlig automat över möjliga fonsekvenser, eller genom 2) en probabilistisk modell där man tränat en n-gram-hanterare på fonsekvenser.
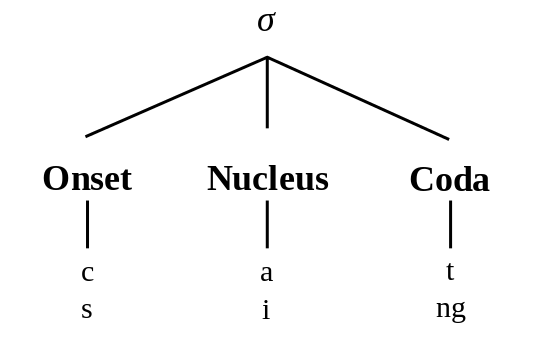
Stavelse med ansats (onset), stavelsekärna (nucleus) och koda (coda) (Wikimedia Commons 2019).
Men vad är då ljud? Ljud är i grund och botten mekaniska vågor som orsakar ändringar i lufttrycket samt kännetecknas av frekvens och amplitud. Frekvens är antalet gånger i sekunden som en våg upprepar sig själv, ofta mätt i cykler per sekund - hertz (Hz) - och där cykeln motsvarar den övre (positiva) och nedre (negativa) delen av vågen. Amplitud avser avståndet mellan ett ytterläge och ett nolläge i en svängningsrörelse, alltså botten och toppen av ljudvågen. Akustisk analys grundar sig i de trigonometriska sinus- och cosinus-funktionerna.
När man gör en analog till digital konverting av ljud (dvs. från analoga elektriska signaler till digitala) ingår två steg: sampling och kvantifiering. Vid sampling av en signal mäter man dess amplitud vid en given tidpunkt. Ju fler samplingar per sekund som görs, desto större amplititudriktighet - men minsta möjliga antal samlplingar är två per cykel. Nyquist-frekvensen (namngiven efter svensk-amerikanen Harry Nyquist som gjorde många bidrag till signalöverföringsforksningen) säger att den kritiska frekvensen för en signal är hälften av samplingsfrekvensen. Kvantifieringen avser representeringen av ljudinput i heltal (eng. integers) - antingen lagrade i 8 eller 16 bitar - med de avrundningar och trunkeringar som detta innebär.
För att mäta genomsnittsamplituden hos en signal använder man det kvadratriska medelvärdet, RMS-amplitiden (eng. root-mean-square), som kvadrerar varje amplitudmätning innan medelvärdet beräknas, för att därefter ta ut roten. Intensiteten av ljudet mäts med logaritmiska decibel-måttet, där effekten delas med ett givet refensvärde, ofta satt till 2 * 10^-5 Pascal, som betraktas som människans hörseltröskel. Intensiteten hänger ihop med den upplevda ljudstyrkan, vilket innebär att ljud med hög amplitud ocskå upplevs som starkare, även om förhållandet inte är helt linjärt eftersom vissa frekvensintervall upplevs som starkare än de egentligen är. Även tonhöjd är en upplevd egenskap hos ljud, som hänger tätt samman med frekvensen hos ljudet. Människor är bäst på att urskilja frekvenser inom intervallet 100-1000 Hz.
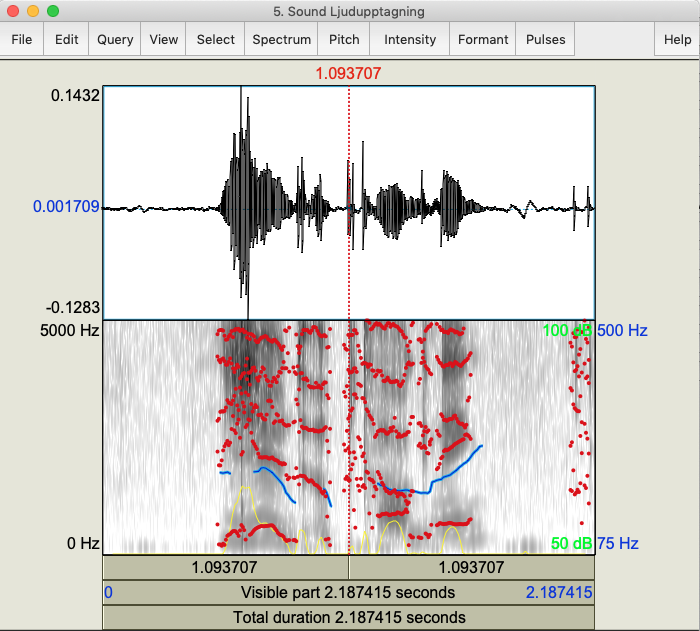
Spektrum och spektrogram av ordet "ljudupptagning" i mjukvaran Praat. Vokalerna syns tydligast.
Vid visuella representationer av ljudvågor i ett spektrum kan man se att vokaler, som ju alltid är tonande, syns allra tydligast eftersom de är längre och starkare än konsonanterna. Klusilerna (eng. stop consonants), t.ex. b, d, och g, känns ofta igen på en period av tysnad och sedan en viss stegring i amplituden när luften som hållits inne frigörs. Frikativerna (eng. fricatives), t.ex. s- och tj-ljudet, känns istället igen på sin lite bullriga och oregelbundna vågformation.
För talforskning och taligenkänning är en annan typ av diagram speciellt användbar, nämligen spektrogrammet. Det visar frekvens vertikalt på y-axeln och tiden på x-axeln, men istället för frekvens vid en given tidpunkt (som i spektret) visas hur olika frekvenser hos vågformationen ändrar sig över tid. Mörkare partier i spektrogrammet visar frekvenskomponenter med hög amplitud och kallas formanter. Dessa ändrar sig inte när tonhöjden ändras och ser annorlunda ut för olika vokaler, vilket gör dem användbara för att identifiera just vokaler, nasalljud samt l- och r-ljudet.
Källa-filter-modellen (eng. source-filter model) är en modell för talproduktion som förklarar hur vibrationer producerade av glottis (röstspringan tillsammans med stämläpparna), källan, och formas av ansatsröret, filtret. De ljudvågor som skapas har också harmoniska bivågor (eng. harmonics) vars frekvens är en faktor av frekvensen hos grundvågen: “Thus, for example, a 115 Hz glottal fold vibration leads to harmonics (other waves) of 230 Hz, 345 Hz, 460 Hz, and so on.” (Jurafsky & Martin 2009:241). Dessa vågor får i allmänhet lägre amplitud än grundvågen. Ansatsrörets utformning, som ju bland annat påverkas av tungans position, gör att vissa ljud kommer att förstärkas och andra att dämpas.