
32. GPU:er, AKA "pinsamt parallella"
GPU står för graphics processing units och är hårdvaran som underlättar maskin- och djupinlärning. I skolan använder vi MLT-programmets egna GPU-processorer (“mltgpu”) för maskininlärning, inklusive NLU-träning (natural language understanding) med Rasa. GPU:er kan ses i kontrast till CPU:er (central processing units), centralprocessorer, som är chip som finns i alla datorer och fungerar som hjärnan i datorn.
CPU:er tar in instruktioner från datorprogram och utför generella beräkningar för att hantera programflöden och minnesdelning. De skickar ut signaler till externa enheter och tar även emot signaler från exempelvis tangentbordet. Tyvärr blir CPU:er ganska långsamma om man vill utföra de beräkningar som görs inom maskininlärning eftersom allting sker sekventiellt.
För den typen av specialiserade beräkningar lämpar sig istället GPU:er bättre där alla beräkningar sker parallellt. Häromdagen stötte jag på begreppet “embarrassingly parallel” apropå GPU:er, vilket verkar vara ett etablerat begrepp. Det har sitt ursprung i att dessa beräkningar visserligen är intensiva men inte nödvändigtvis komplicerade eftersom allting kan brytas ner i mindre, oberoende räkneuppgifter.
GPU:er utvecklades från början för dataspelsgrafik där man snabbt vill manipulera skärmens pixlar som var och en representerar en upsättning siffror för färgkoder. Den här manipuleringen av stora sifferområden är väldigt lik matris- och tensoroperationerna som utförs inom maskininlärning, med den enda skillnaden att vi inte manipulerar konkreta bilder på skärmen, utan mer abstrakta entititer. Något som bidrar till att göra GPU:erna snabbare än CPU:erna är antalet processorkärnor (eng. cores). Medan CPU:er brukar ha 4, 8 eller 16 kärnor så kan GPU:er ha hundratals [1].
Institutionens mltgpu består av fyra GPU:er som köptes in för ungefär 3 år sedan. Eftersom varje GPU har ett begränsat minne måste vi dela på resurserna och vara medvetna om vilken av dessa fyra vi använder. För att kolla GPU:ernas status kan man köra kommandot nvidia-smi. Nvidia är pionjärföretaget som lanserade sin första GPU år 1999 och som är en av de två stora tillverkarna (den andra är AMD). Utöver hårdvaran tillkommer också ett mjukvarulager kallat cuda som ger utvecklararna en API att arbeta mot. Cuda kan installeras gratis från Nvidias hemsida och innehåller olika bibliotek, bland annat cuDNN (cuda deep learning neural network) för djupinlärning.
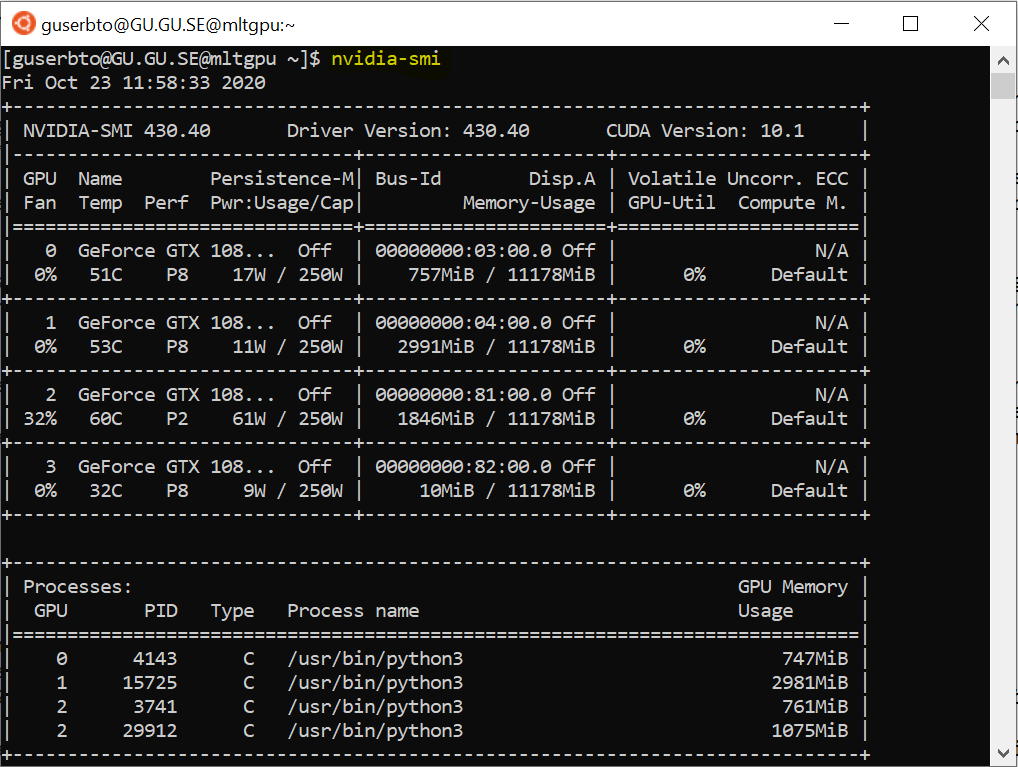
Tabellen visar de fyra GPU:erna och hur mycket av deras minne (11mb var) som används samt wattförbrukning. Den undre rutan visar vilka processer som pågår just nu.
Fun fact: Maskininlärningsbiblioteket Pytorch kan användas som kontaktyta mellan mjukvarulagret cuda och de applikationer vi vill bygga. Genom att kalla Pytorch-metoden cuda() på en tensor flyttar man över den från CPU:n till GPU:n.
[1] Rekommenderar den här videon från Youtube-kontot deeplizard apropå GPU:er.