
18. "I am sorry to hear you are depressed"
Chattbottar och dialogsystem har varit lite av nisch hos MLT-programmet i och med en obligatorisk grundkurs och en valbar fortsättningskurs i ämnet. I motsvarande kapitel hos Jurafsky och Martin (2021, 3:e upplagan) görs en uppdelning i uppgiftsorienterade dialogsystem, som hjälper till med saker som att spela musik, hitta närliggande restauranger eller ringa upp någon åt dig (tänk Google Assistant och liknande röststyrda system), och regelrätta chattbottar, vars syfte är att kunna hålla igång naturlig konversation så länge som möjligt, något som exempelvis universitetslag tävlar om i Amazons årliga Alexa-pristävling.
Chattbottar
För den senare typen beskriver Jurafsky och Martin om tre olika sorters chattbotsarkitektur:
1) regelstyrda system
2) IR-styrda system
3) kodare-avkodare-generatorer
Den första typen - de rent regelstyrda systemen - återfinnar man främst i de tidigaste chattbottarna. Det kändaste exemplet är antagligen ELIZA, en chattbot från 60-talet som i enlighet med den Rogerianska grenen av kliniskt psykologi programmerats för att upprepa patientens yttranden, samt ställa földjfrågor utifrån nyckelord och klassiska frågor av typen “Hur får det dig att känna?”. Nyckelorden får då olika rankningar utifrån hur generella eller specifika de är. Tack vare minnesstacken kan programmet också återuppta ämnen som nämnts tidigare i samtalet (“Earlier you said that you…“).

Exempel på samtal med ELIZA (Weizenbaumm 1966).’
Den andra två typerna av chattbotsarkitektur förlitar sig istället för regler på korpusar med transkriptioner av andra samtal, något som kräver enorma mängder data. Ett av de äldre transkriberade korpusarna är Switchboard-korpuset med 260 timmar tal från tidiga 90-talet, medan Topical Chat och EmpatheticDialogues är exempel på nyare så kallade crowd-sourcade korpusar där personer anlitats för att simulera olika typer av känsobaserade eller ämnesstyrda konversationer. Dessa korpusar är stora men inte tillräckligt stora för att användas isolerat, därför förtränas ofta chatbottar på filmdialoger och sociala medie-korpusar.
De IR-styrda systemen (eller informationshämtningsbaserade systemen, från eng. information retrieval) använder sig av olika algoritmer för att givet användarens indata hitta ett lämpligt svar i en sådan korpus. Antingen brukar de försöka hitta det yttrande i korpusen som har högst cosinus-likhet med användarens senaste yttrande, och ge det svar som följer på det, eller så jämförs indatat med alla tänkabara svar i korpusen rakt av, utifrån tanken att ett passande svar borde dela många ord med själva indatasträngen. Intressant nog, påpekar Jurafsky & Martin (2019), verkar den senare strategin fungera bättre.
Den andra korpusbaserade ansatsen med kodare-avkodare-generatorer gör istället ett försök att själv generera ett svar utifrån användarens indatayttrande och korpusen den tränats på: “An alternate way to use a corpus to generate dialogue is to think of response generation as a task of transducing from the user’s prior turn to the system’s turn. This is basically the machine learning version of Eliza; the system learns from a corpus to transduce a question to an answer” (2021: kaptiel 24: sida 11). I ett sådant system genereras ett svarsord i taget utifrån användarens indatasträng och de senast genererade orden i svaret.
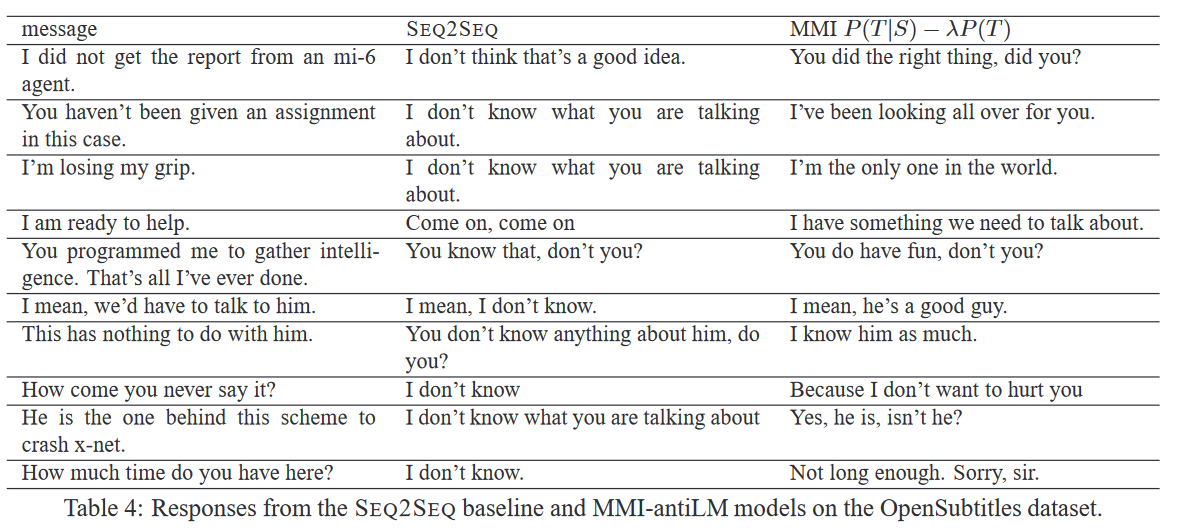
Jämförelse mellan traditionell seq2seq och Maximum Mutual Information-metoden (Li et al. 2016).
För att undvika repetetiva och tråkiga svar av typen “jag vet inte” - som den här så kallade seq2seq-ansatsen annars tenderar att generera - har forskarna bland annat lanserat Maximum Mutual Information-funktionen, se ovan (Li et al. 2016). Ett annat problem - med såväl IR-baserada som kodare-avkodare-baserade system - är att de i sin enklaste form inte tar hänsyn till den större kontexten när de genererar tänkbara svar. Li et al. (2017) har använt sig av något som kallas adversarial training för att förbättra den övergripande relevansen hos svaren:
“A good dialogue model should generate utterances indistinguishable from human dialogues. Such a goal suggests a training objective resembling the idea of the Turing test (Turing, 1950). We borrow the idea of adversarial training (Goodfellow et al., 2014; Denton et al., 2015) in computer vision, in which we jointly train two models, a generator (a neural SEQ2SEQ model) that defines the probability of generating a dialogue sequence, and a discriminator that labels dialogues as human-generated or machine-generated. This discriminator is analogous to the evaluator in the Turing test. We cast the task as a reinforcement learning problem, in which the quality of machine-generated utterances is measured by its ability to fool the discriminator into believing that it is a human-generated one. The output from the discriminator is used as a reward to the generator, pushing it to generate utterances indistinguishable from human-generated dialogues.
Uppgiftsorienterade system
När det kommer till uppgiftsorienterade system nämner Jurafsky & Martin (2021) två stora arkitekturer: 1) GUS- och 2) dialoge state-aritekturen. Båda baserar sig på konceptet med frames: “A frame is a kind of knowledge frame structure representing the kinds of intentions the system can extract from user sentences, and consists of a collection of slots, each of which can take a set of possible values. Together this set of frames is sometimes called a domain ontology.” (2021: kapitel 24: sida 13). Beroende av typen av domän man rör sig i kan en slot då motsvara en maträtt (t.ex. take-away-dialogsystem) eller ett datum, klockslag eller en destination (biljettbokningssystem). Många system arbetar efter dessa ramar och slots, och fyller i ett inre formulär allteftersom användaren uppger mer information. De kvarstående formulärrutorna dikterar vilka följdfrågor som ställs.
Eftersom många system tillhandahåller flera olika ramar, t.ex. ett biljettbokningssystem som också erbjuder hotellreservation, innebär det att systemet måste ha en villkorsbaserad kontrollfunktion för att veta när den ska hoppa vidare till frågor gällande en annan ram, och ha koll på vilka frågor som fortfarande är relevanta att ställa. Men innan några formulärfönster (slots) ens fylls i måste först domänet som användarens yttranden berör klassificeras, och därefter användarens avsikt. I de ursprungliga modellerna av GUS-arkitekturen användes otaliga handskrivna regler med reguljära uttryck för att matcha yttranden mot avsikt och formulärifyllning. Det moderna system är, som så mycket annat inom dagens språkteknologi, ofta maskininlärningsbaserade snarare än regelstyrda, även om den underliggande arkitekturen med forumlär och ramar fortfarande är densamma.
Den andra typen av uppgiftsorienterade system, dialogue-state-arkitekturen, beskrivs som en mer sofistikerad version av frame-arkitekturen. Begreppet dialogue state (som jag väljer att kalla dialogtillstånd) verkar användarens yttrande i form av en talakt, dvs vilket syfte yttrandet har där och då i dialogen (är det att informera? bekräfta? undersöka?), i kombination med de tidigare nämnda formulärrutorna (slots). Eftersom dialoge-state-arkituren ofta grundar sig i maskininlärning måste systemen tränas i att korrekt identifiera dialogtillståden (med hänsyn på slots, domän, avsikt), exempelvis genom BERT.
Den här typen av system användar sig av dialogue-state trackers för att hålla koll på användarens senaste dialogtillstånd och ramen i sin nuvarande helhet (dvs vilka rutor som är ifyllda). Ofta tränas trackern på annoterad dialogdata, men i sin allra enklaste form kan den använda utdatat från formulärifyllningen för att bestämma dialogtillståndet.
![]()
Exempel på dialogue-state-tracking (Jurafsky & Martin 2019).
Om användaren säger något fel och därför vill korrigera sig själv, måste systemet även kunna identifiera korrigeringsakten, vilket är lättare sagt än gjort. Människor som korrigerar sig själva tenderar att hyperartikulera (“Jag sa STO-CK-HOLMMMM”), något som paradoxalt nog kan göra det svårare för taligenkänningskomponenten i systemet att förstå. Men i kombination med andra vanligt förekommande korrigeringsmönster (tex svärord!) kan systemet ändå tränas till att bättre uppfatta korrigeringar som just rättning av äldre information, och inte helt ny sådan.
Andra viktiga delar i dialogtillståndssystemet är dialogue policy, vars syfte är att sätta rätt handling som svar på andvändarens input. Detta genom att exempelvis beräkna sannolikheten för att man uppfattat användarens indata rätt, vilket kan ske genom att BEKRÄFTA, eller helt sonika AVSLÅ begäran med “Ursäkta, jag uppfattade inte vad du sa”. Den muntliga eller skriftliga realiseringen av detta kallas natural language generation (NLG).