
37. Kodare-avkodare-modeller och uppmärksamhet
Kodare-avkodare-modeller (som jag väljer att kalla dem) kallas encoder-decoder models eller sequence-to-sequence models (aka seq2seq) på engelska och är nätverk som är bra på att generera kontextanpassade utdatasekvenser av godtycklig längd (Jurafsky & Martin 2020: kap 10). De tidigaste artiklarna från 2014 använder den här typen av neuralt nätverk för att förbättra maskinöversättning mellan franska och engelska, men enligt Jurafsky & Martin har kodare-avkodare-modellerna också visat sig användbara för automatisk textsammanfattning, fråga/svar- och dialogmodellering (ibid).
Kodare-avkodare-modeller består av två nätverk – en kodare (eng. encoder) och en avkodare (eng. decoder) – med vanligtvis samma arkitektur, dvs. ett återkopplande neuralt nätverk (RNN) (Jurafsky & Martin 2020: kap 10). Kodaren har som uppgift att ta in en indatasekvens och skapa en kontextuell representation av den som avkodaren sedan använder sig av för att generera en utdatasekvens (ibid).
De traditionella RNN-baserade språkmodellerna skapas genom att utifrån textkorpora träna upp ett nätverk i att förutspå nästa ord i en sekvens, något som går under benämningen autoregressiva modeller (Jurafsky & Martin 2020: kap 10). En sådan modell kan utifrån en ett godtyckligt valt startord generera en fortsättningssekvens där de genererade orden grundar sig på vad som är mest sannolikt givet det gömda stadiet (eng. hidden state) från föregående tidssteg – som innehåller hela den bakre sekvenskontexten – samt inbäddningen (eng. embedding) för det senast genererade ordet. Detta pågår tills man når en slutet-på-meningen-tagg, <\s> (ibid).
I maskinöversättningssammanhang kan man då utifrån parallella korpora konkatenera käll- och målspråkets respektiva strängar (åtskiljda av källspråkets slutet-på-mening-tagg) för att träna upp modellen. Detta möjliggör nämligen för nätverket att koppla ihop källspråkets sträng med målspråkets översättning genom den kontext som källspråkets slutet-på-mening-tagg för med sig genom det gömda lagret i föregående tidssteg in i översättningsgenereringen (Jurafsky & Martin 2020: kap 10).
En kodare-avkodare-modell följer i grund och botten samma princip, fast med två RNN (kodare och avkodare). Kodaren tar in en sträng av godtycklig längd och generarar en kontextuell representation som är resultatet av det sista gömda lagret i kodaren. En kontextvektor – som är en funktion av den här kontextuella representationen – matas in i avkodaren som steg för steg generar en utdatasekvens av godtycklig längd. Men! Det går att göra den här processen ännu bättre genom att låta kontextvektorn hänga med i beräkningen av varje gömt lager i översättningen, så att signalen från den inte försvagas på vägen.
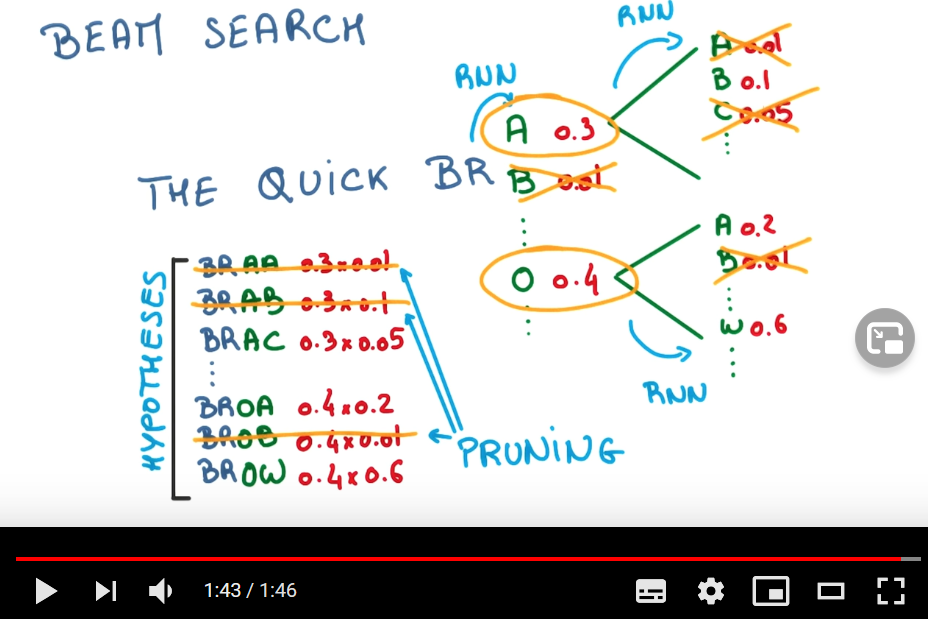
För att ytterligare säkerställa att det som genereras inte bara är det mest troliga utifrån kontexten, utan också passar ihop totalt sett, kan man applicera något som kallas beam search. Den här knappt två minuter långa videon beskriver kortfattat hur den här tekniken fungerar (applicerad på en karaktärsbaserad istället för ordbaserad modell, men jag tolkar det som att principen är densamma för ordbaserade modeller):
Avslutningsvis, låt oss prata uppmärksamhet (eng. attention). En nackdel med kontextvektorn som genereras från det sista gömda lagret i kodaren är att den tenderar att vara mer fokuserad på slutdelen av indatasträngen snarare än strängen som helhet och dess individuella delar. Ett banbrytande sätt att lösa detta på är att ersätta den statiska kontextvektorn med en kontextvektor som uppdateras dynamiskt utifrån varje gömt lager i kodaren varje gång som det sker en beräkning i avkodaren.
För att undersöka vilket gömt lager i kodaren som är mest relevant för den nuvarande beräkningen i avkodaren tar vi den inre produkten av var och ett av de gömda lagren i kodaren och det senaste gömda lagret i avkodaren och beräknar likheten. Man kan sedan, beroende på syftet med nätverket, förfina den här likhetspoängen genom att applicera vikter på den, “[…] giving the network the ability to learn which aspects of similarity between the decoder and encoder states are important to the current application” (Jurafsky & Martin 3:e upplagans utkast: kap 11: sida 13). Till sist normaliseras likhetspoängen med ett softmax-lager för att skapa en viktvetkor som uttrycker hur viktigt var och ett av de gömda lagren är för det nuvarande tillståndet i avkodaren.