
53. Latent semantisk analys
Latent semantisk analys (eng. latent semantic analysis) (LSA) är en oövervakad, statistisk metod för att analysera dolda (“latenta”) relationer mellan dokument utifrån de ord som förekommer i dem. Det används bland annat för att identifiera ämnen i dokumentsamlingar (eng. topic recognition).
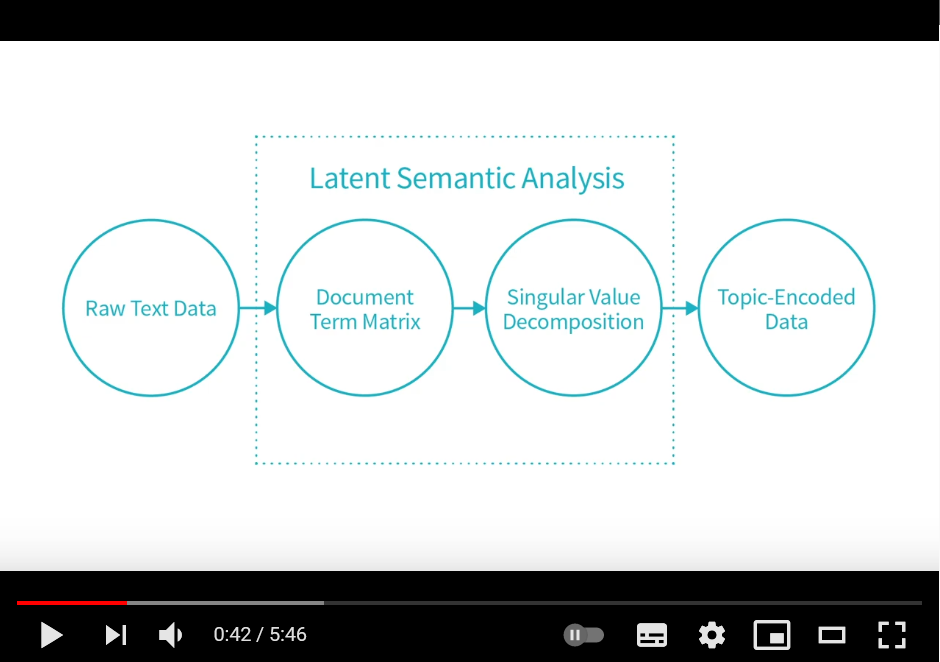
Klicka på bilden för att komma till en videotutorial för hur man kan implementera LSA med scikit-learn.
När LSA introduceras i en artikel av Deerwester et al. 1990 var det effektivare informationssökning (eng. information retrieval) som var målet för metoden: “The problem is that users want to retrieve on the basis of conceptual content, and individual words provide unreliable evidence about the conceptual topic or meaning of a document.” Två specifika problem som lyfts fram är synonymi (att användare kan använda andra, liknande söktermer än de som förekommer i dokumentet –> sämre täckning) och polysemi (att ord kan ha flera betydelser –> sämre precision).
Tanken är att det finns en slags underliggande semantisk struktur i dokumenten som döljs av “the randomness of word choice with respect to retrieval” (Deerwester et al. 1990:1) och att det gäller att förstå vad användaren egentligen letar efter. Man ger följande exempel: “[S]uppose that in our total collection the words ‘access’ and ‘retrieval’ each occurred in 100 documents, and that 95 of these documents containing ‘access’ also contained ‘retrieval’. We might reasonably guess that the absence of ‘retrieval’ from a document containing ‘access’ might be erroneous, and consequently wish to retrieve the document in response to a query containing only ‘retrieval’.” (Deerwester et al. 1990:3).
Den matematiska tekniken man använder för att lösa det här problemet kallas singulärvärdesuppdelning (eng. singular value decomposition) (SVD) på svenska. Exakt hur SVD fungerar får vänta tills jag hunnit läsa någon kurs i linjär algebra, men i kort så handlar det om att omvandla en hög-dimensionell term-dokument-matris med tillhörande frekvenser (dvs. hur många gånger varje ord i vokabuläret förekommer i varje dokument) till en låg-dimensionell dito genom dimensionsreducering. Detta sker genom att vissa dimensioner slås ihop och blir beroende av flera termer (t.ex. båt och skepp). Det bidrar till att brus (eng. noise) från enstaka ordförekomster försvinner och att synonymer tas i beaktning. Dokumenen kan sedan jämföras mot varandra och även mot söktermerna med hjälp av cosinus-likhet.
Värt att notera är att de resulterande dimensionerna ibland kan vara svåra att tolka (Wikipedia-artikeln om LSA har ett bra exempel under Limitations) och dessutom skilja sig lite från gång till gång. SVD/LSA är också beräkningsmässigt en ganska tung operation som kräver mycket minne.
Fun fact: När man använder LSA i informationshämtningssammanhang brukar det istället kallas latent semantisk indexering (eng. latent semantic indexing) (LSI).
Referenser
- Latent Semantic Analysis, Wikipedia, 07-09-2021.
- Indexing by Latent Semantic Analysis. Scott Deerwester, Susan T. Dumais, Richard Harshman. 1990.
- A Trivial Implementation of LSA using Scikit Learn (2/5), YouTube, 07-09-2021.
- Föreläsningsslides från andra föreläsningen i kursen Machine Learning for Statistical NLP (LT2222), VT 2021.