
46. Maskininlärning, djupinlärning och AI
I den här texten tänkte jag försöka reda ut skillnaden mellan maskininlärning (ML), djupinlärning (DL) och artificiell intelligens (AI).
Maskininlärning är ett stort forskningsområde (som även innefattar djupinlärning) och som i kort går ut på att lära datorer att hitta mönster i data som sedan kan generaliseras till osedd data. ML kan delas in i övervakad och icke-övervakad inlärning (eng. supervised/unsupervised learning), där den förra använder data som annoterats med de kategorier eller klasser man vill kunna förutspå, medan den senare använder ouppmärkt data. Övervakad inlärning är vanligast både inom ML och DL, men icke-övervakad inlärning används för bland annat klusteranalys och inte minst för att skapa ordinbäddningar.
Konventionell maskininlärning har länge använt sig av handplockade features (ofta utvalda av en domänexpert) för att träna datamodeller. Inom t.ex. sentimentanalys kan det innebära att man förlitar sig på närvaron av specifika nyckelord, emojis, punktuation, negation m.m. för att träna upp en modell att klassificera en recension som positiv, negativ eller neutral [1]. Inom datorseendefältet kan handplockade features för att upptäcka cancerceller i tredimensionella röntgenbilder vara exempelvis bildintensitet, topologisk struktur och textur [2]. Den här typen av ML dominerade länge och handplockade features kan än idag vara värdefulla när man inte har så mycket annoterad data att tillgå [2]. Men de kan vara tidskrävande att ta fram och kan dessutom missa mer komplexa mönster i datat.
Djupinlärning är en gren av ML där datorn själv får undersöka rådatat för att upptäcka värdefulla mönster som kan användas som prediktorer i klassificeringen. DL-metoder är “djupa” eftersom de består av flera icke-linjära neuronlager som successivt bidrar till en mer komplex representation [3]:
“An image, for example, comes in the form of an array of pixel values, and the learned features in the first layer of representation typically represent the presence of absence of edges at particular orientations and locations in the image. The second layer typically detects motifs by spotting particular arrangements of edges, regardless of small variations in the edge positions” (LeCun et al. 2015).
DL drar alltså nytta av det faktum att features på högre nivå ofta är uppbyggda av features på lägre nivå. Precis som objekt i en bild är uppbyggda av kanter, streck och konturer i specifika kombinationer, så är exempelvis meningar i naturligt språk uppbyggda av ord, stavelser, bokstavstecken, fonem och foner.
Artificiell intelligens beskrivs i den engelskspråkiga Wikipedia-artikeln som intelligens uppvisad av maskiner. Men i vår AI-kurs i MLT-programmet har AI snarare handlat om s.k. “situated agents”, dvs program eller robotar som genom sensorer tillåts interagera med sin omgivning. Ta till exempel en objektsklassificerare som lär sig nya objekt genom en kamerasensor, eller en robot som med hjälp av människors instruktioner lär sig hitta nya färdvägar eller skapa inre represenationer av en kontorsbyggnad och dess olika rum.
Ofta brukar skillnaden mellan AI, ML och DL illustreras som tre överlappande cirklar där AI är den yttersta cirkeln, med ML som underfält till AI och DL som och underfält till ML:
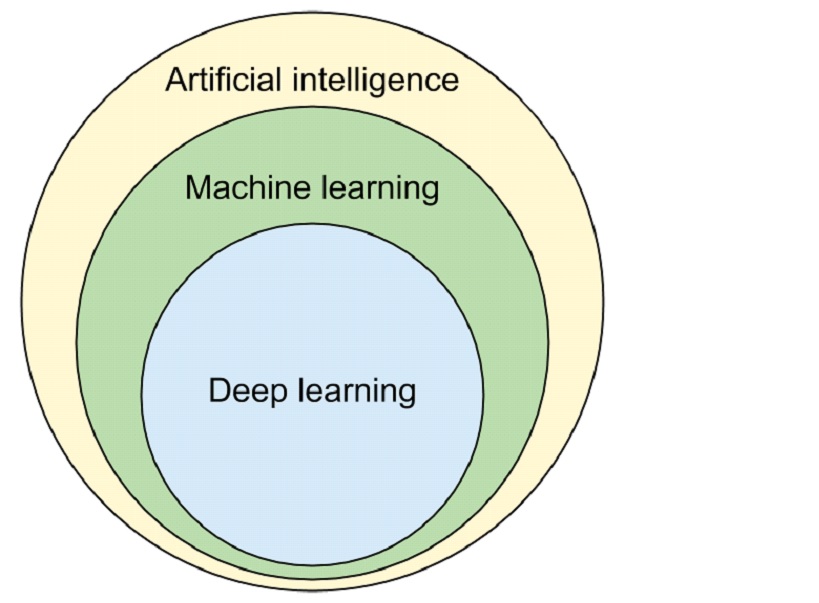
Yakoove, CC BY-SA 4.0, via Wikimedia Commons
{kind=link}
Detta skulle innebära att all form av ML (och DL) också är AI. Men utifrån definitionen av AI som jag tar med mig från MLT-programmet skulle deras inbördes ordning snarare se ut så här:
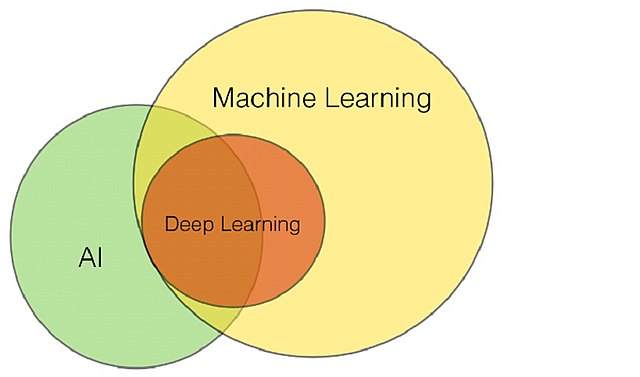
Yakoove, CC BY-SA 4.0, via Wikimedia Commons
{kind=link}
Enligt den här sättet att illustrera fälten är inte all ML som görs per automatik också AI, utan det krävs exempelvis någon form av interaktion med omgivningen i samband med inlärningen.