
3. NLP-forskning nu och i framtiden
I en intressant artikel [1] från tidskriften IEEE Computational Intelligence Magazine från 2014 beskriver författarna Cambria och White det språkteknologiska landskapet så som det såg ut då, och siar om hur det kommer att utveckla sig de närmaste årtiondena. Även om den har några år på nacken så ger den ändå en hygglig introduktion till ämnesområdet och de tekniker som används.
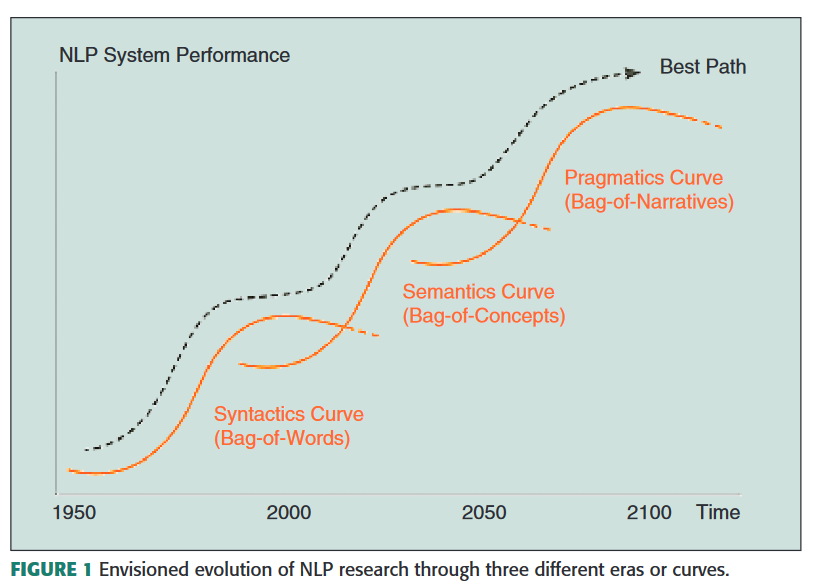
Språkteknologins utveckling framöver, enligt Cambria och White (2014).
De börjar med att konstera att NLP-forskningen, trots internets och sociala mediers genomslag samt den enorma mängden data detta generar, i stort sett har stått och stampat på samma ställe de senaste 15 åren (dsv mellan 1999-2014) - nämligen i den syntatiska kurvan: “Today, most of the existing approaches are still based on the syntactic representation of text, a method that relies mainly on word co-occurrence frequencies. Such algorithms are limited by the fact that they can process only the information that they can ‘see’” [1]. Människor hanterar därför – än så länge – saker som semantisk tvetydighet och underförstådda samband i texter bättre än datorer.
För att språkteknologin på allvar ska gå in i nästa utvecklingsfas - den semantiska kurvan - krävs det att datorer kan ta del av den kunskap som människor ackumulerar under hela sin uppväxt och vuxna liv: common sense-kunskap och allmän omvärldskunskap: “Common-sense, in particular, is key in properly deconstructing natural language text into sentiments according to different contexts—for example, in appraising the concept ‘small room’ as negative for a hotel review and ‘small queue’ as positive for a post office, or the concept ‘go read the book’ as positive for a book review but negative for a movie review” [1]. För att bättre förstå omvärlden – och därigenom förbättra sökmotoroptimeringen – har bland andra Google tagit fram och patenterat en egen databas för att kartlägga relationen mellan olika entiteter, t.ex. “USA:s president” och “Donald Trump” samt allt däremellan (partner, födelseort, förmögenhet, etc) [2].
Den tredje och sista fasen som författarna förutspår är den så kallade pragmatiska kurvan. I det stadiet förstår maskinen inte bar innehållet på synatisk och semantisk nivå, utan kan också tolka det utifrån kontexten och därmed förstå avsikten: “Intent, in particular, will be key for tasks such as sentiment analysis— a concept that generally has a negative connotation, e.g., small seat, might turn out to be positive, e.g., if the intent is for an infant to be safely seated in it” [1]. Även om språkteknologin inte är där riktigt än finns det exempel på forskning som rör sig ditåt. Man nämner Patrick Winstons datamodeller för narrativ, som utgår tanken om att mänsklig intelligens grundar sig i historieberättande. Utifrån detta har man utvecklat progroammet Genesis System, som med hjälp av “low-level common sense rules and higher level reflection patterns” [1], har kunnit lista ut att en sammanfattning av Shakespeares Macbeth och händelserna kring det rysk-estniska cyberkriget 2007 både grundar sig i hämnd - trots att vare sig begreppet hämnd eller dess synonymer förekommer i texterna.
Jag fortfarande är en novis i ämnet språkteknologi, som till en början kommer att fokusera på teorier och tekniker på främst syntaktiskt plan. Men jag ser fram emot att lära mig mer om forskning och applikationer kring de högre nivåerna längre fram. :D