
36. Symbolförankringsproblemet
I kursen AI: kognitiva system läser vi den här veckan artiklar med koppling till det som jag väljer att kalla symbolförankringsproblemet på svenska, och som går under benämningen symbol grounding problem (Harnad 1990) på engelska. Symbolförankringsproblemet har sitt urprung i kognitionsforskningens (och semantikens) försök att modellera hur vi människor kopplar ihop ord (och andra symboler) med deras respektive betydelser – vilket i sin tur väcker frågan vad betydelse eller mening egentligen är (Symbol grounding problem, 11-11-2020).
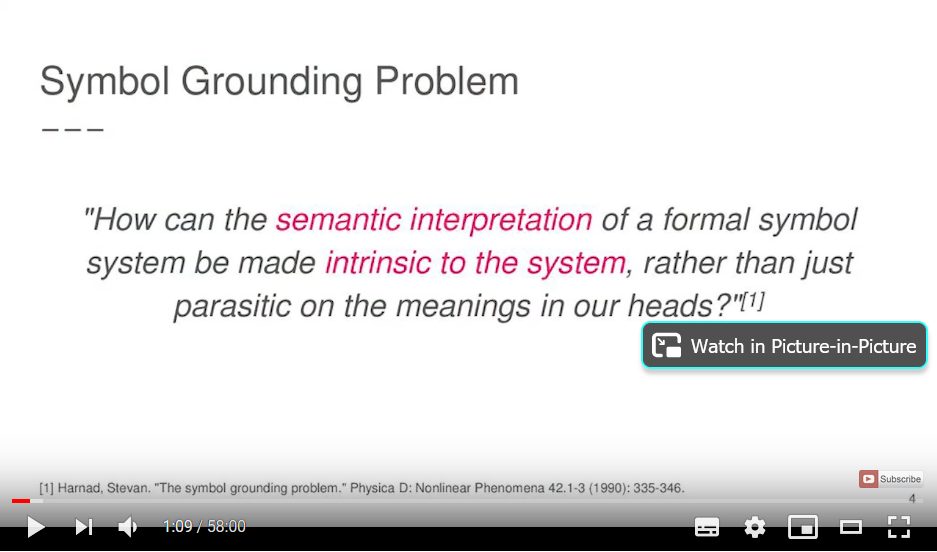
I sin artikel från 1990 beskriver Stevan Harnad två sätt att se på det mänskliga sinnet: som ett symbolsystem där kognition är ett uttryck för symbolmanipulering, eller ett system (oklart i vilken form) där kognition istället kan ses som dynamiska aktiveringsmönster i flerlagriga nätverk där noderna har positivt eller negativt viktade kopplingar (Harnad 1990:337). Det första sättet att se det på det kallas symbolisk AI grundar sig på antagandet om att fysiska symbolsystem är fullt tillräckliga för att skapa intelligenta beteenden.
Vad är då ett symbolsystem? Ett symbolsystem består av en uppsättning godtyckliga fysiska tecken (eng. arbitrary physical tokens), som kan vara ord i ett språk, 1:or och 0:or i en dator eller schackpjäserna i ett schackspel. Dessa kan manipuleras enligt explicita regler som även de är fysiska tecken och teckensträngar. Den här manipuleringen är rent syntaktisk och sker enbart på basis av formen hos symboltecknen och inte deras bakomliggande betydelse. Det handlar om att regelmässigt kombinera och omkombinera symboltecken.
Det finns enkla atomiska symboltecken (eng. atomic symbol tokens) och sammansatta symbolteckensträngar (eng. composite symbol token strings). Hela den här uppsättningen av atomiska och sammansatta symboler, regler samt manipuleringar är att betrakta som semantiskt tolkningsbar (eng. semantically interpretable): “The syntax can be systematically assigned a meaning” (Harnad 1990:336). Enligt anhängarna av den här modellen kan exempelvis tankar och övertygelser i det mänskliga sinnet då ses som symbolsträngar.
Nackdelen med det här sättet att se på det mänskliga sinnet och dess kognition illustreras av filosofen John Searles kinesiska rum. Det kinesiska rum-argumentet ifrågasätter det intelligenta i simulera mänskligt beteende enbart på basis av symboltecken. En dator som genom algoritmerna i ett datorprogram kan ta en uppsättning kinesiska tecken som indata och mata ut en annan uppsättning kinesiska tecken tillräckligt övertygande för att klara Turing-testet har egentligen inte någon förståelse för tecknens betydelse.
Harnad bygger vidare på den här analogin genom ett exempel med en kinesisk-kinesisk ordbok. En person som lär sig kinesiska som andraspråk skulle potentiellt – utifrån sin kunskap om världen och sitt egna förstaspråk – kanske kunna lära sig kinesiska genom en sådan ordbok. Det skulle vara svårt, men kanske inte omöjligt. Det finns ju trots allt kryptologer och forskare i utdöda, historiska språk som lyckas med just detta. Men betydelsen av orden är då förankrad (eng. grounded) i den här externa kunskapen, inte i symbolsystemet självt. En person utan den här kunskapen, som ska lära sig kinesiska som förstaspråk med ordboken som enda källa till information, skulle däremot ha en omöjlig uppgift framför sig. För hur kan man förstå betydelsen av godtyckliga tecken enbart utifrån andra godtyckliga tecken?
Lösningen som Harnad presenterar på det här s.k. symbolförankringsproblemet är ett symboliskt/icke-symboliskt hybridsystem där symboltecknen är förankrade i två ickesymboliska representationer: ikoniska och kategoriska representationer. De ikoniska representationerna är enbart inre analoga representationer av de objekt vi kan se rent fysiskt med våra ögon: “[i]n the case of horses (and vision), they would be analogs of the many shapes that horses cast on our retinas” (Harnad 1990:342). De inre ikonerna är egentligen det enda som krävs för att kunna särskilja (eng. discriminate) en häst från en annan häst. Men särskiljning är inte samma sak som identifiering; att kunna särskilja en häst från en annan häst kräver egentligen inga kunskaper om konceptet häst.
För att kunna identifiera en häst med epitetet häst när vi ser den måste vi ha ett begrepp om vad kategorin häst innebär. Kategoriseringen sker genom att reducera de ikoniska representationerna av hästar till deras oföränderliga egenskaper (eng. invariant features), d.v.s. de egenskaper som tillåter oss att med viss säkerhet identifiera något som en häst. Resultatet av den här reduceringen kallas alltså kategoriska representationer.
Såväl ikoniska som kategoriska representationer är icke-symboliska. För att göra de kategoriska representationerna semantiskt tolkningsbara måste de knytas ihop till påståenden (eng. propositions) av typen “zebra” = “häst” + “ränder”, där “ränder” är en annan kategorisk representation (baserad på reducerade ikoner av just objekt med ränder). Zebra ärver den ikoniska och kategoriska förankringen hos “häst” och “ränder” genom symbolisk representation. En person som är helt ovetande om konceptet zebror men som känner till hästar och ränder skulle då kunna förstå sig på vad en zebra innebär utifrån den symboliska representationen “zebra” = “häst” + “ränder”.
Det andra sättet att se på kognition, som ett slags neuralt nätverk, kallas konnektionism (eng. connectionism) och erbjuder en förklaringsmeknism för hur vi skapar de ovan nämnda kategoriska representationerna. Genom att mentalt bearbeta ikoniska representationer av nya, okända objekt tillsammans med deras korrekta etikett kan vi tids nog lära oss att justera vår inre kategoriska representation av det nya objektet. Det viktiga är att det sker någon form av feedback (genom de korrekta etiketterna) så att vi lär oss. Det här sker hela tiden (om jag inte fått det hela om bakfoten), men kanske framför allt när vi som barn lär oss nya objektskategorier och ord.
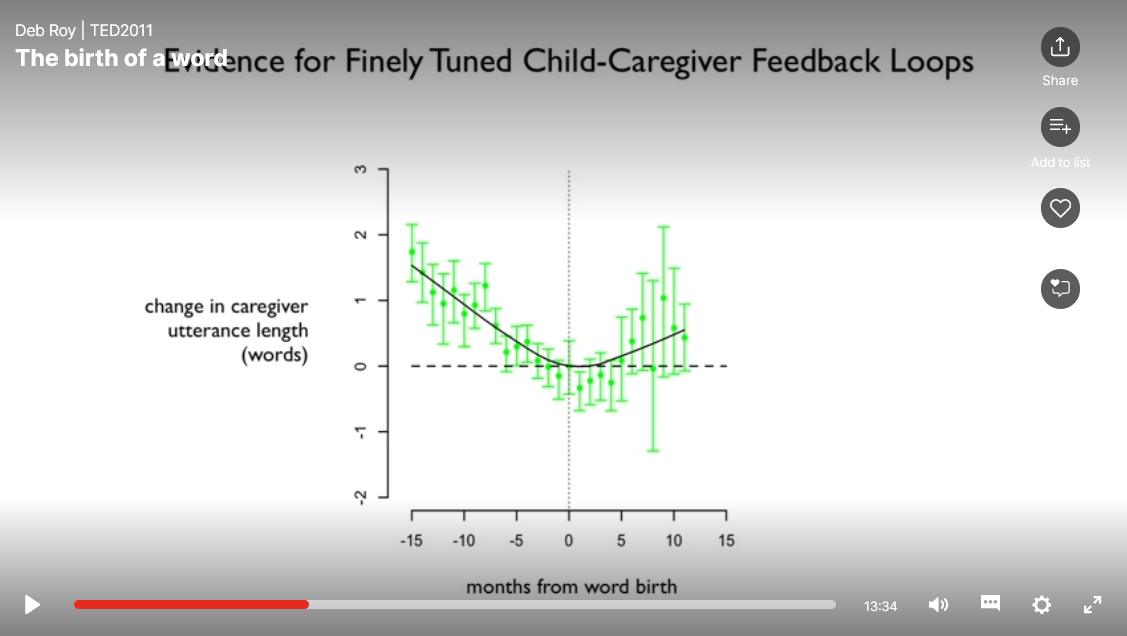
I den här fascinerande TEDtalk-videon från 2011 beskriver MIT-forskaren Deb Roy hur han genom tiotusentals timmars video- och ljudupptagningar från det egna hemmet kunde följa sin sons språkutveckling under över fem års tid. Genom att analysera ljuddatat kunde de sätta alla ord som sonen lärt sig under sina första år i livet i relation till (så gott som) alla yttranden från föräldrarna och barnvakten där samma ord använts under den här tidpunkten.
Analysresultatet visade bland annat att komplexiteten i de vuxnas meningar till sonen var som allra enklast i de ögonblick han lärde sig de nya orden: “So it appears that all three primary caregivers – myself, my wife and our nanny – were systematically and, I would think, subconsciously restructuring our language to meet him at the birth of a word and bring him gently into more complex language. And the implications of this – there are many, but one I just want to point out, is that there must be amazing feedback loops.” (Roys TEDtalk 2011, 6 min in).
Fun fact: Stevan Harnad är utöver kognitionsforskare även en engagerad djurrättare och vegan som är chefredaktör för en akademisk journal med fokus på djurs förmåga att känna känslor: Animal Sentience. <3