
45. Utvärdera mera!
Låt oss kika på några vanliga utvärderingsmått för klassificering och textgenerering.
Binär klassificering
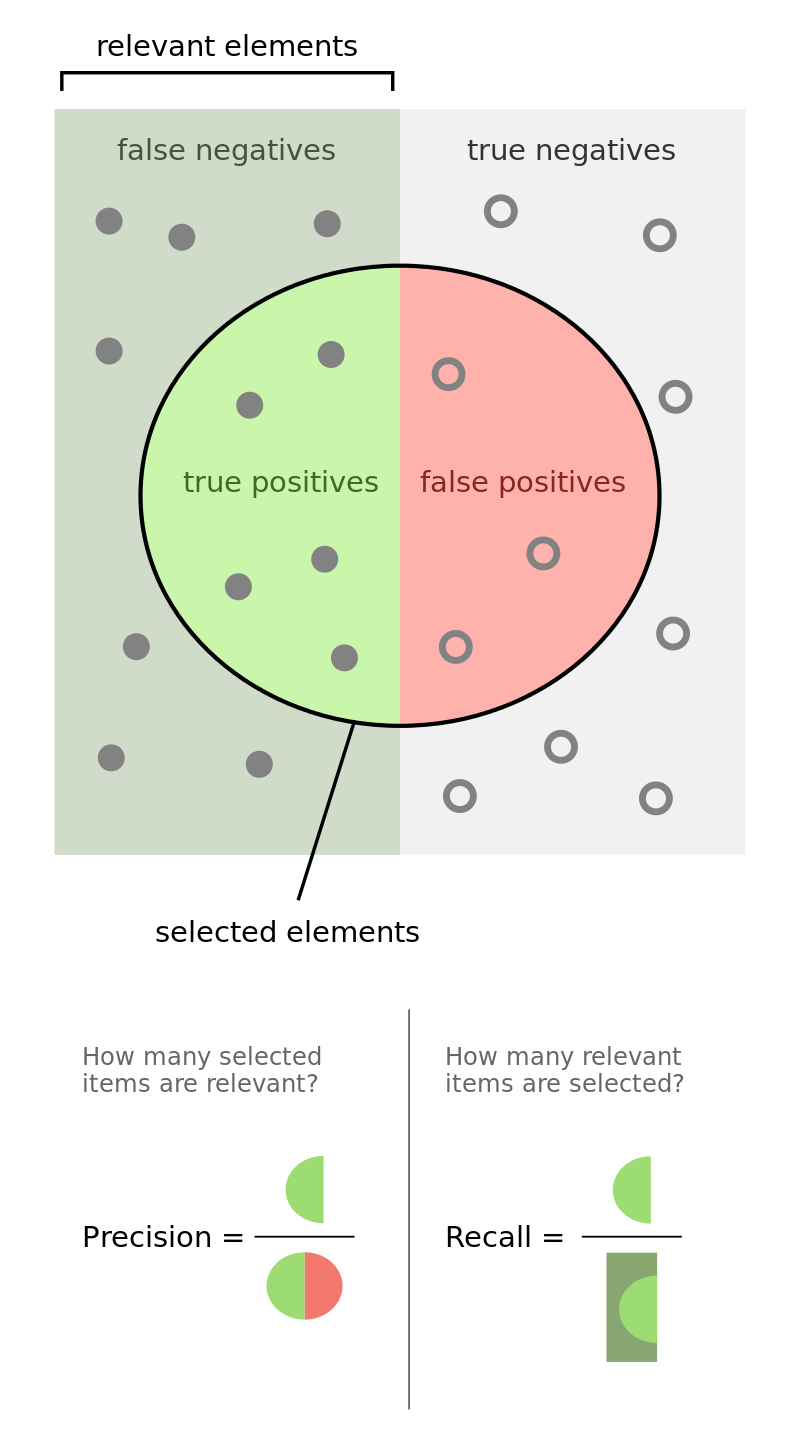
Några av de första mätmetoderna jag stötte på under MLT-programmet var accuracy, precision, recall och F1 - som alla används flitigt för binära klassificeringsuppgifter inom maskininlärning, t.ex. att identifiera en tweet som positiv eller negativ. De grundar sig på antalet true positives (TP, tweets korrekt klassificerade som positiva), true negatives (TN, korrekt klassificerade som negativa), false positives* (FP, felaktigt klassificerades som positiva) och false negatives (FN, felaktigt klassificerades som negativa).
Den första, accuracy (kanske noggrannhet eller riktighet på svenska?) kan definieras som antalet riktiga klassificeringar delat med det totala antalet klassificeringar - mer formellt så här:
\[\text{accuracy} = \frac{TP + TN}{TP + TN + FP + FN}\]Notera att accuracy kan bli missvisande vid obalanserade dataset. Om en datasamling med tweets för sentimentanalys innehåller 80 % positiva tweets och 20 % negativa, så skulle en modell som klassificerar alla tweets som positiva ge 80 % noggrannhet.
Walber, CC BY-SA 4.0, via Wikimedia Commons
{kind=link}
Precision är ett mått på relevanta klassficeringar och avser andelen tweets som korrekt klassificerades som positiva (TP) sett i relation till det totala antalet tweets som klassificerades som positiva (TP + FP):
\[\text{precision} = \frac{TP}{TP + FP}\]Recall avser återkallesegraden hos resultaten, dvs. hur många av de positiva tweeten i datasamlingen (TP + FN) som korrekt klassificerades som positiva (TP):
\[\text{recall} = \frac{TP}{TP + FN}\]F1 tar både precision och recall i beaktning och beskrivs av Wikipedia som ett harmoniskt medelvärde av dessa:
\[\text{F1} = 2 \cdot \frac{\text{precision} \cdot \text{recall}}{\text{precision} + \text{recall}}\]Så hur skiljer sig F1 från accuracy? Enligt den här towardsdatascience-artikeln av Cristopher Riggio ger F1 större vikt till false positives och false negatives och mindre vikt till true negatives. Detta illustreras i bilden nedan där sammma dataset och utfall ger 90 % accuracy och F1-värdet 0:
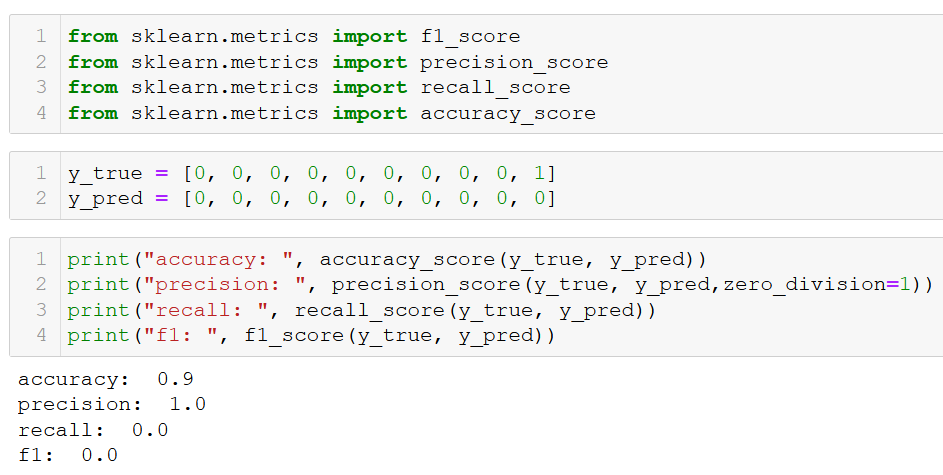
Enligt den här Medium-artikeln av Purva Huigol är F1 ett bättre mått än accuracy när det råder obalans i datasetet (vilket det ofta gör i praktiken).
Flerklassklassificering
Vid klassificering med fler än två klasser (där varje objekt bara kan tillhöra en klass) finns det två angreppssätt: micro- och macromedelvärde av precisionen.
Micromedelvärdet (eng. micro averaging) innebär att man tar TP, TN, FP och FN för varje enskild klass och sedan behandlar allt tillsammans:
\[\text{precision_micro} = \frac{TP_a + TP_b + ... + TP_k }{(TP_a + TP_b + ... TP_k) + (FP_a + FP_b + ... FP_k)}\]Det här sättet att beräkna medelvärdet av precisionen ger varje observation i testdatat samma vikt (Vaughan 2020).
Macromedelvärdet (eng. macro averaging) innebär istället att man först beräknar den enskilda precisionen ($ P_{klass} = \frac{TP}{TP+FP} $) för varje klassetikett och sedan dividerar med antalet klasser (k):
\[\text{precision_macro} = \frac{P_a + P_b + ... + P_k }{k}\]Det här sättet att beräkna medelvärdet av precisionen ger varje klass i testdatat samma vikt (Vaughan 2020).
Det här svaret i forumet StackExchange illustrerar det här bra med ett enkelt exempel.
Textgenerering
När det kommer till maskinöversättning och andra typer av textgenererande uppgifter är det istället ett annat utvärderingsmått som brukar användas: BLEU (BiLingual Evaluation Understudy). Tanken bakom BLEU är att den maskingenererade översättningen borde innehålla många av de ord och fraser som återfinns i den människoskrivna översättningen av samma text - ju fler desto bättre (Jurafsky & Martin onlineutkast 2021: kap 11).
Med BLEU mäter man därför antalet överlappande n-gram mellan maskinöversättningen och facitöversättningen, sk. n-gramsprecision. Engramsprecision innebär då att man tar antalet 1-gram i maskinöversättningen som även förekommer i facit och delar det med det totala antalet löpord i maskinöversättningen. I den här artikeln på temat bildtextsgenerering används BLEU med 1-gram upp till och med 4-gram i jämförelsen mot andra modeller. Ju större n-gram man använder, desto lägre BLEU-värde får man. Om den genererade översättningen är kortare än referensöversättningen får den poängavdrag. Och för att förhindra att meningar som bara innehåller repetitioner av ord som förekommer i facit får ett bra BLEU-värde tar man också antalet gånger löpordet förekommer i facitmeningen i beaktning.
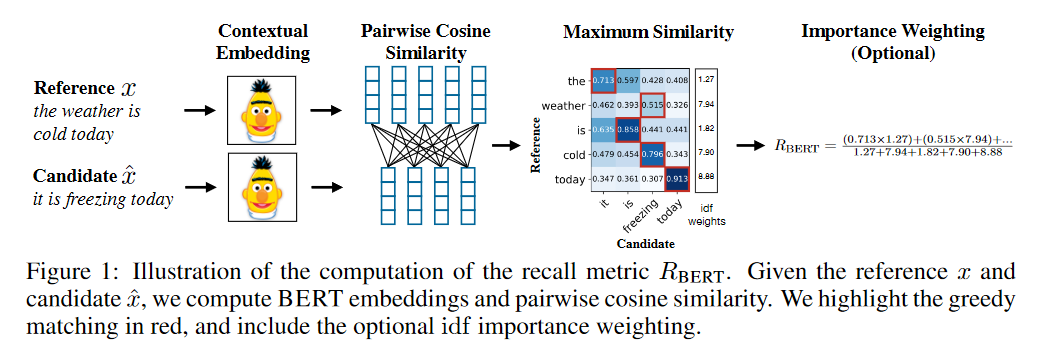
Illustration över BERTScore från Zhang et al. (2020). Det här måttet möjliggör jämförelse mellan två meningar som är semantiskt lika trots att de inte delar så många löpord.
Eftersom BLEU inte fångar upp synonymer och omskrivningar i översättningen har det också dykt upp andra utvärderingsmetoder. Ett av de tidigaste alternativen var METEOR (Banerjee et al. 2005), som tar just tar hänsyn till bland annat synonymer. Nu för tiden finns också ordinbäddningsbaserade metoder som använder BERT, exempelvis BERTScore som togs fram av Zhang et al. (2020). För generering av bildtexter finns CIDEr (Vedantam et al. 2015), ett konsensusbaserat mått som belönar meningar som liknar majoriteten av de människoskrivna texterna för samma bild (bildtextkorpusar som MSCOCO har oftast flera alternativa bildtexter för samma bild).