
40. Visuellt grundade metaforer, AKA "himmel + eld = solnedgång"
Spanar på idéer till projekt för AI-kursen och läser därför en artikel av Bizzoni och Dobnik (2020) som handlar om likheterna mellan visuellt grundade metaforer (gjorda av människor) och de missbedömningar som bildklassificerare ibland gör när de konfronteras med nya objekt. De undersöker till vilken grad man kan utnyttja den här mekanismen för att efterlikna mänskligt metaforskapande.
Man definierar visuellt grundade metaforer (eng. visually grounded metaphors) som metaforer som baserar sig på synliga likheter mellan två objekt, ofta gjorda i syfte att ge en mer levande beskrivning av intrycket som någon eller något gör på en. Man ger som exempel att beskriva en stor person som en “elefant” eller att jämföra någons blåa ögon med en “klar sommarhimmel”. Två relevanta termer i det här sammanhanget är mål (eng. target) – som referar till målobjektet “blå ögon” – och källa (eng. source) som refererar till källan för metaforen: “klar sommarhimmel”.
Bozzoni och Dobnik använder sig av förtränade objektklassificerare tillgängliga i Keras: ResNet50, VGG16, VGG19 och InceptionResNet. För studiens syfte begränsar de sig till 1000 förtränade objektkategorier från ImageNet. Modellerna 1) tar en bild som indata, 2) omvandlar den till en vektor som fångar upp huvuddragen (eng. main features) i bilden m.h.a. de förtränade vikterna, samt 3) ger en sannolikhetsbaserad klassificering av bilden. I och med att modellerna enbart tränats på 1000 objekt kommer vissa av klassificeringarna att bli felaktiga.

Manetgalax.
(NASA Goddard Space Flight Center from Greenbelt, MD, USA, Public domain, via Wikimedia Commons)
De samlar också in data från internetsökningar bestående av 100 bilder med tillhörande människoskrivna metaforer, t.ex. en bild på en galax som beskrivs som en manet, eller en bild på blixtrar som beskrivs som spindelnät. Varken galaxer eller blixtrar finns med bland de förtränade 1000 objekten, men det gör däremot beskrivningarna (manet, spindelnät). Det intressanta blir då att se vilken sannolikhet modellerna tillskriver de människogenererade beskrivningarna.
Man undersökte detta på samtliga modeller och fann att majoriteten av dem gav ett F-mått på mellan 0,23 och 0,26 om man begränsade sig till den mest sannolika objektskategorin. Om man utökade utvärderingen till de 5 mest troliga kategorierna ökade detta till mellan 0,30 och 0,40. Och för de 20 mest sannolika kategorierna översteg F-måttet 0,50. De skriver: “Considering the complexity of the task, we see F-scores of 0.3 and higher for the first 5 answers as an interesting result” (Bizzoni & Dobnik 2020:4).
I den andra delen av studien ville man undersöka om det går att beräkningsmässigt återskapa kompositionaliteten i metaforer som “solnedgång är himlen som brinner” eller “snö är en vit matta”. Detta gjorde man genom att ta några bilder på en solnedgång, summera deras vektorer och skapa en gemensam solnedgångsvektor. Man gjorde detsamma för eld och himmel och och jämförde sedan cosinuslikheten mellan dessa tre vektorer.
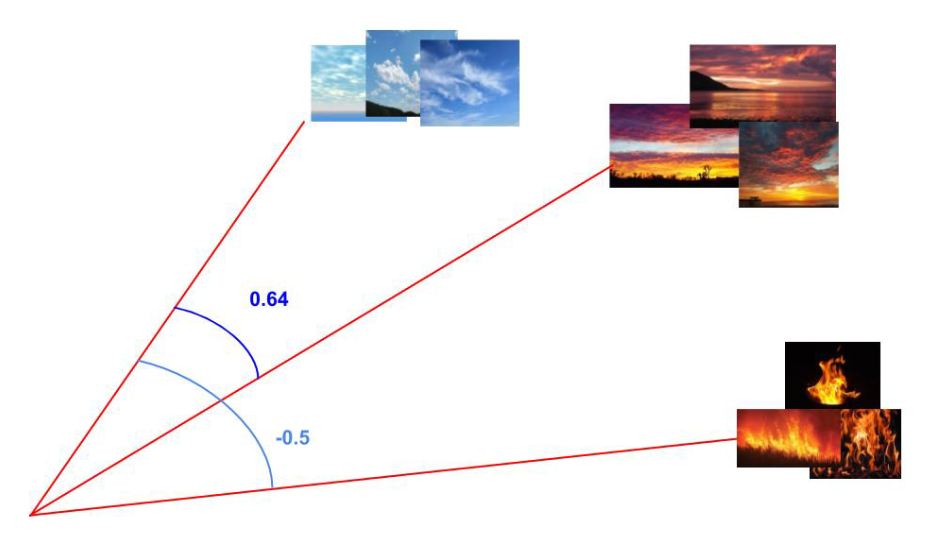
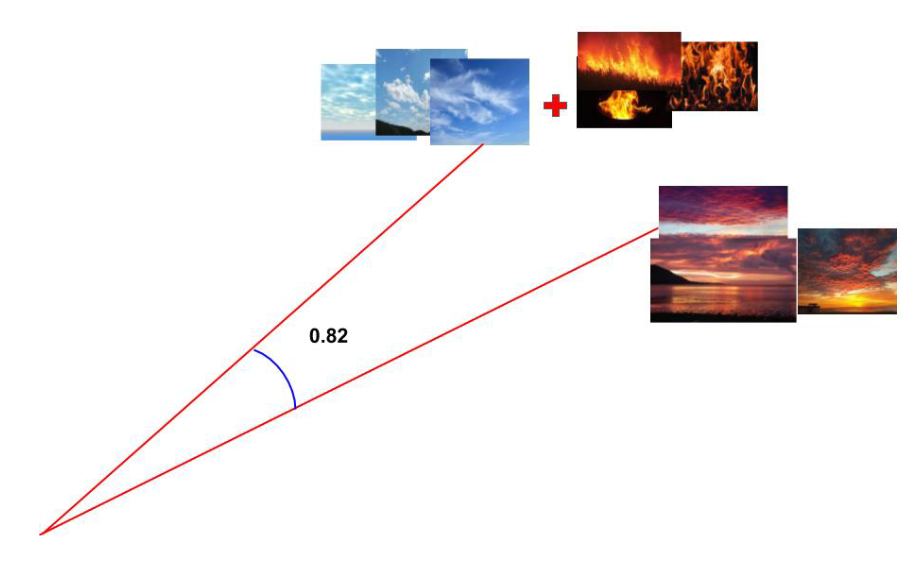
Cosinuslikheten mellan himmelvektorn och solnedgångsvektorn var 0,64. Mellan himmelvektorn och eldvektorn var den däremot negativ: -0,5. Men det visade sig att om man summerade himmelvektorn med eldvektorn för att skapa en syntetisk solnedgångsvektor och jämförde den mot den ursprungliga solnedgångsvektorn så ökade cosinuslikheten från 0,64 till 0,82.
Man gjorde detsamma för 21 andra metaforer med stark visuell koppling (t.ex. “blont hår är floder av guld”) och upptäckte samma mönster. Komponenter som sinsemellan inte uppvisar särskilt hög likhet – “blont hår” och “floder” – får ökad cosinuslikhet när man summerar källobjektet med en modifierare (“floder” + “guld”) och jämför på nytt. Tillförlitligheten i detta samband stärktes av att s.k. falska metaforer inte uppvisade samma mönster utan istället fick sämre cosinuslikhet av den här proceduren.
Referenser
- Y. Bizzoni and S. Dobnik. 2020. Sky + fire = sunset. Exploring parallels between visually grounded metaphors and image classifiers. I: Proceedings of the Second Workshop on Figurative Language Processing (FLP) at ACL-2020, pages 126–135, Online, July 2020. Association for Computational Linguistics.